KubeDB simplifies Provision, Upgrade, Scaling, Volume Expansion, Monitor, Backup, Restore for various Databases in Kubernetes on any Public & Private Cloud
task_altLower administrative burden
task_altNative Kubernetes Support
task_altPerformance
task_altAvailability and durability
task_altManageability
task_altCost-effectiveness
task_altSecurity
A complete Kubernetes native disaster recovery solution for backup and restore your volumes and databases in Kubernetes on any public and private clouds.
task_altDeclarative API
task_altBackup Kubernetes Volumes
task_altBackup Database
task_altMultiple Storage Support
task_altDeduplication
task_altData Encryption
task_altVolume Snapshot
task_altPolicy Based Backup
KubeVault is a Git-Ops ready, production-grade solution for deploying and configuring Hashicorp's Vault on Kubernetes.
This is an Enterprise-only feature. Please install Stash Enterprise Edition to try this feature. You can use KubeDB Enterprise license to install Stash Enterprise edition. Database backup with Stash is already included in the KubeDB Enterprise license. So, you don’t need a separate license for Stash.
Percona XtraDB Backup & Restore Overview
KubeDB uses Stash to backup and restore databases. Stash by AppsCode is a cloud native data backup and recovery solution for Kubernetes workloads. Stash utilizes restic to securely backup stateful applications to any cloud or on-prem storage backends (for example, S3, GCS, Azure Blob storage, Minio, NetApp, Dell EMC etc.).
Fig: Backup KubeDB Databases Using Stash
How Backup Works
The following diagram shows how Stash takes backup of a Percona XtraDB database. Open the image in a new tab to see the enlarged version.
Fig: Percona XtraDB Backup Overview
The backup process consists of the following steps:
At first, a user creates a secret with access credentials of the backend where the backed up data will be stored.
Then, she creates a Repository crd that specifies the backend information along with the secret that holds the credentials to access the backend.
Then, she creates a BackupConfiguration crd targeting the AppBinding crd of the desired database. The BackupConfiguration object also specifies the Task to use to backup the database.
Stash operator watches for BackupConfiguration crd.
Once Stash operator finds a BackupConfiguration crd, it creates a CronJob with the schedule specified in BackupConfiguration object to trigger backup periodically.
On the next scheduled slot, the CronJob triggers a backup by creating a BackupSession crd.
Stash operator also watches for BackupSession crd.
When it finds a BackupSession object, it resolves the respective Task and Function and prepares a Job definition to backup.
Then, it creates the Job to backup the targeted database.
The backup Job reads necessary information to connect with the database from the AppBinding crd. It also reads backend information and access credentials from Repository crd and Storage Secret respectively.
Then, the Job dumps the targeted database(s) and uploads the output to the backend. Stash pipes the output of the dump command to the upload process. Hence, backup Job does not require a large volume to hold the entire dump output.
Finally, when the backup is complete, the Job sends Prometheus metrics to the Pushgateway running inside Stash operator pod. It also updates the BackupSession and Repository status to reflect the backup procedure.
Backup Different Percona XtraDB Configurations
This section will show you how backup works for different Percona XtraDB Configurations.
Standalone Percona XtraDB
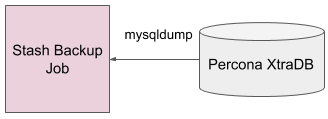
For a standalone Percona XtraDB database, the backup job directly dumps the database using mysqldump and pipe the output to the backup process.
Fig: Standalone Percona XtraDB Backup
Percona XtraDB Cluster
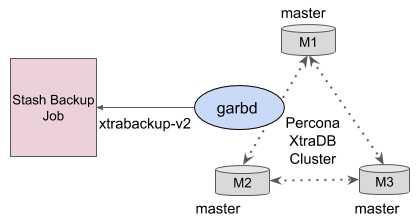
For a standalone Percona XtraDB database, the backup Job runs the backup procedure to take the backup of the targeted databases and uploads the output to the backend. In backup procedure, the Job runs a process called garbd (Galera Arbitrator) which uses xtrabackup-v2 script during State Snapshot Transfer (SST). Basically this Job takes a full copy of the data stored in the data directory (/var/lib/mysql) and pipes the output of the backup procedure to the uploading process. Hence, backup Job does not require a large volume to hold the entire backed up data.
Fig: Percona XtraDB Cluster Backup
How Restore Process Works
The following diagram shows how Stash restores backed up data into a Percona XtraDB database. Open the image in a new tab to see the enlarged version.
Fig: Percona XtraDB Restore Process Overview
The restore process consists of the following steps:
At first, a user creates a RestoreSession crd targeting the AppBinding of the desired database where the backed up data will be restored. It also specifies the Repository crd which holds the backend information and the Task to use to restore the target.
Stash operator watches for RestoreSession object.
Once it finds a RestoreSession object, it resolves the respective Task and Function and prepares a Job (in case of restoring cluster more than one Job and PVC) definition(s) to restore.
Then, it creates the Job(s) (as well as PVCs in case of cluster) to restore the target.
The Job(s) reads necessary information to connect with the database from respective AppBinding crd. It also reads backend information and access credentials from Repository crd and Storage Secret respectively.
Then, the Job(s) downloads the backed up data from the backend and injects into the desired database. Stash pipes the downloaded data to inject into the database. Hence, the restore Job(s) does not require a large volume to download entire backup data inside it.
Finally, when the restore process is complete, the Job(s) sends Prometheus metrics to the Pushgateway and update the RestoreSession status to reflect restore completion.
Restore Different Percona XtraDB Configurations
This section will show you how restore works for different Percona XtraDB Configurations.
Standalone Percona XtraDB
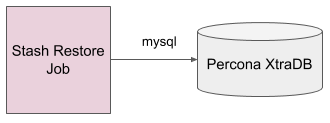
For a standalone Percona XtraDB database, the restore Job downloads the backed up data from the backend and pipe the downloaded data to mysql command which inserts the data into the desired database.
Fig: Standalone Percona XtraDB Restore
Percona XtraDB Cluster
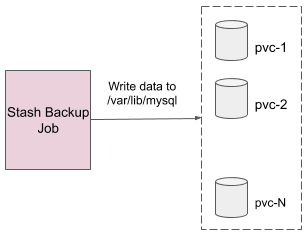
For a Percona XtraDB Cluster, the Stash operator creates a number (equal to the value of .spec.target.replicas of RestoreSession object) of Jobs to restore. Each of these Jobs requires a PVC to store the previously backed up data of the data directory /var/lib/mysql from the backend. Then each Job downloads the backed up data from the backend and injects into the associated PVC.
Fig: Percona XtraDB Cluster Restore
Next Steps
Backup a standalone Precona XtraDB server using Stash by following the guides from here.
Backup a Precona XtraDB cluster using Stash by following the guides from here.