New to KubeDB? Please start here.
Database Scheduled Snapshots
This tutorial will show you how to use KubeDB to take scheduled snapshot of a MySQL database.
Before You Begin
-
At first, you need to have a Kubernetes cluster, and the kubectl command-line tool must be configured to communicate with your cluster. If you do not already have a cluster, you can create one by using Minikube.
-
Now, install KubeDB cli on your workstation and KubeDB operator in your cluster following the steps here.
-
To keep things isolated, this tutorial uses a separate namespace called demo throughout this tutorial. Run the following command to prepare your cluster for this tutorial:
$ kubectl create ns demo
namespace/demo created
Note: The yaml files that are used in this tutorial are stored in docs/examples folder in GitHub repository kubedb/cli.
Scheduled Backups
KubeDB supports taking periodic backups for a database using a cron expression. KubeDB operator will launch a Job periodically that runs the mysql dump command and uploads the output bson file to various cloud providers S3, GCS, Azure, OpenStack Swift and/or locally mounted volumes using osm.
In this tutorial, snapshots will be stored in a Google Cloud Storage (GCS) bucket. To do so, a secret is needed that has the following 2 keys:
| Key |
Description |
GOOGLE_PROJECT_ID |
Required. Google Cloud project ID |
GOOGLE_SERVICE_ACCOUNT_JSON_KEY |
Required. Google Cloud service account json key |
$ echo -n '<your-project-id>' > GOOGLE_PROJECT_ID
$ mv downloaded-sa-json.key > GOOGLE_SERVICE_ACCOUNT_JSON_KEY
$ kubectl create secret generic my-snap-secret -n demo \
--from-file=./GOOGLE_PROJECT_ID \
--from-file=./GOOGLE_SERVICE_ACCOUNT_JSON_KEY
secret/my-snap-secret created
$ kubectl get secret my-snap-secret -n demo -o yaml
apiVersion: v1
data:
GOOGLE_PROJECT_ID: PHlvdXItcHJvamVjdC1pZD4=
GOOGLE_SERVICE_ACCOUNT_JSON_KEY: ewogICJ0eXBlIjogInNlcnZpY2VfYWNjb3V...9tIgp9Cg==
kind: Secret
metadata:
name: my-snap-secret
namespace: demo
...
type: Opaque
To learn how to configure other storage destinations for Snapshots, please visit here. Now, create the MySQL object with scheduled snapshot.
apiVersion: kubedb.com/v1alpha1
kind: MySQL
metadata:
name: mysql-scheduled
namespace: demo
spec:
version: "8.0-v2"
storage:
storageClassName: "standard"
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
backupSchedule:
cronExpression: "@every 1m"
storageSecretName: my-snap-secret
gcs:
bucket: kubedb-qa
$ kubedb create -f https://raw.githubusercontent.com/kubedb/cli/0.12.0/docs/examples/mysql/snapshot/demo-4.yaml
mysql.kubedb.com/mysql-scheduled created
It is also possible to add backup scheduler to an existing MySQL. You just have to edit the MySQL CRD and add below spec:
$ kubedb edit my {db-name} -n demo
spec:
backupSchedule:
cronExpression: '@every 1m'
gcs:
bucket: kubedb-qa
storageSecretName: my-snap-secret
Once the spec.backupSchedule is added, KubeDB operator will create a new Snapshot object on each tick of the cron expression. This triggers KubeDB operator to create a Job as it would for any regular instant backup process. You can see the snapshots as they are created using kubedb get snap command.
$ kubedb get snap -n demo
NAME DATABASENAME STATUS AGE
mysql-scheduled-20180927-083539 mysql-scheduled Succeeded 3m
mysql-scheduled-20180927-083639 mysql-scheduled Succeeded 2m
mysql-scheduled-20180927-083739 mysql-scheduled Succeeded 1m
mysql-scheduled-20180927-083839 mysql-scheduled Succeeded 39s
you should see the output of the mysql dump command for each snapshot stored in the GCS bucket.
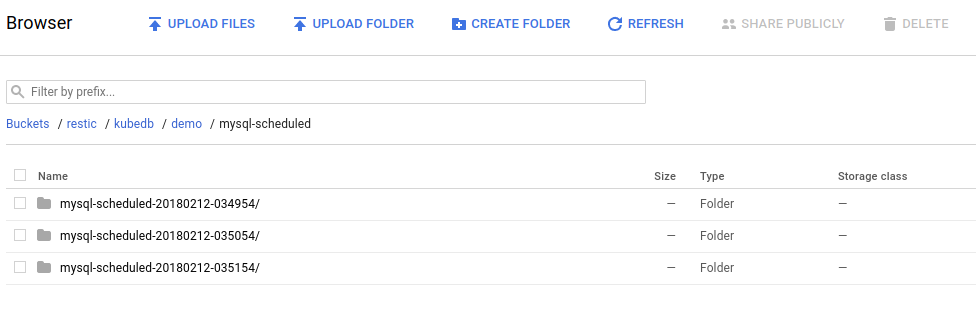
From the above image, you can see that the snapshot output is stored in a folder called {bucket}/kubedb/{namespace}/{mysql-object}/{snapshot}/.
Remove Scheduler
To remove scheduler, edit the MySQL object to remove spec.backupSchedule section.
$ kubedb edit my mysql-scheduled -n demo
apiVersion: kubedb.com/v1alpha1
kind: MySQL
metadata:
name: mysql-scheduled
namespace: demo
...
spec:
# backupSchedule:
# cronExpression: '@every 1m'
# gcs:
# bucket: kubedb-qa
# storageSecretName: my-snap-secret
databaseSecret:
secretName: mysql-scheduled-auth
storage:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
storageClassName: standard
version: 8
status:
phase: Running
Customizing backupSchedule
You can customize pod template spec and volume claim spec for the backup jobs by customizing backupSchedule section.
Some common customization examples are shown below:
Specify PVC Template:
Backup jobs use temporary storage to hold dump files before it can be uploaded to cloud backend. By default, KubeDB reads storage specification from spec.storage section of database crd and creates a PVC with similar specification for backup job. However, if you want to specify a custom PVC template, you can do it through spec.backupSchedule.podVolumeClaimSpec field. This is particularly helpful when you want to use different storageclass for backup jobs and the database.
apiVersion: kubedb.com/v1alpha1
kind: MySQL
metadata:
name: mysql-scheduled
namespace: demo
spec:
version: "8.0-v2"
storage:
storageClassName: "standard"
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
backupSchedule:
cronExpression: "@every 1m"
storageSecretName: my-snap-secret
gcs:
bucket: kubedb
podVolumeClaimSpec:
storageClassName: "standard"
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi # make sure size is larger or equal than your database size
Specify Resources for Backup Jobs:
You can specify resources for backup jobs through spec.backupSchedule.podTemplate.spec.resources field.
apiVersion: kubedb.com/v1alpha1
kind: MySQL
metadata:
name: mysql-scheduled
namespace: demo
spec:
version: "8.0-v2"
storage:
storageClassName: "standard"
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
backupSchedule:
cronExpression: "@every 1m"
storageSecretName: my-snap-secret
gcs:
bucket: kubedb
podTemplate:
spec:
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
Provide Annotations for Backup Jobs:
If you need to add some annotations to backup jobs, you can specify those in spec.backupSchedule.podTemplate.controller.annotations. You can also specify annotations for the pod created by backup jobs in spec.backupSchedule.podTemplate.annotations field.
apiVersion: kubedb.com/v1alpha1
kind: MySQL
metadata:
name: mysql-scheduled
namespace: demo
spec:
version: "8.0-v2"
storage:
storageClassName: "standard"
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
backupSchedule:
cronExpression: "@every 1m"
storageSecretName: my-snap-secret
gcs:
bucket: kubedb
podTemplate:
annotations:
passMe: ToBackupJobPod
controller:
annotations:
passMe: ToBackupJob
Pass Arguments to Backup Jobs:
KubeDB allows users to pass extra arguments for backup jobs. You can provide these arguments via spec.backupSchedule.podTemplate.spec.args field of a Snapshot crd.
apiVersion: kubedb.com/v1alpha1
kind: MySQL
metadata:
name: mysql-scheduled
namespace: demo
spec:
version: "8.0-v2"
storage:
storageClassName: "standard"
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
backupSchedule:
cronExpression: "@every 1m"
storageSecretName: my-snap-secret
gcs:
bucket: kubedb
podTemplate:
spec:
args:
- --extra-args-to-backup-command
Cleaning up
To cleanup the Kubernetes resources created by this tutorial, run:
kubectl patch -n demo mysql/mysql-scheduled -p '{"spec":{"terminationPolicy":"WipeOut"}}' --type="merge"
kubectl delete -n demo mysql/mysql-scheduled
kubectl patch -n demo drmn/mysql-scheduled -p '{"spec":{"wipeOut":true}}' --type="merge"
kubectl delete -n demo drmn/mysql-scheduled
kubectl delete ns demo
Next Steps























